Section:
New Results
Semantic Event Fusion of Different Visual Modality Concepts for Activity Recognition
Participants :
Carlos Fernando Crispim-Junior, François Brémond.
Keywords: Knowledge representation formalism and methods, Uncertainty and probabilistic reasoning, Concept synchronization, Activity recognition, Vision and scene understanding, Multimedia Perceptual System,
Combining multimodal concept streams from heterogeneous sensors is a problem superficially explored for activity recognition. Most studies explore simple sensors in nearly perfect conditions, where temporal synchronization is guaranteed. Sophisticated fusion schemes adopt problem-specific graphical representations of events that are generally deeply linked with their training data and focus on a single sensor. In this work we have proposed a hybrid framework between knowledge-driven and probabilistic-driven methods for event representation and recognition. It separates semantic modeling from raw sensor data by using an intermediate semantic representation, namely concepts. It introduces an algorithm for sensor alignment that uses concept similarity as a surrogate for the inaccurate temporal information of real life scenarios (Fig. 20 ). Finally, it proposes the combined use of an ontology language, to overcome the rigidity of previous approaches at model definition, and a probabilistic interpretation for ontological models, which equips the framework with a mechanism to handle noisy and ambiguous concept observations, an ability that most knowledge-driven methods lack (Fig. 19 ). We evaluate our contributions in multimodal recordings of elderly people carrying out instrumental activities of daily living (Table 11 ). Results demonstrated that the proposed framework outperforms baseline methods both in event recognition performance and in delimiting the temporal boundaries of event instances
This work has been developed as a collaboration between different teams in Dem@care consortium (Inria, University of Bordeaux, and CERTH). We thank the other co-authors for their contributions and support in the development of this work up to its submission for publication.
Table
11. Comparison to baseline methods in the test set
|
mean -score
|
Fusion approach
|
|
Baselines
|
Ours
|
| IADL |
SVM |
OSF |
|
| S. bus line |
44.19 |
31.36 |
73.10 |
| M.finances |
43.99 |
0.00 |
43.73 |
| P. pill box |
45.86 |
49.11 |
65.02 |
| P. drink |
20.02 |
24.29 |
64.03 |
| Read |
90.18 |
91.82 |
95.22 |
| T.telephone |
72.12 |
0.00 |
75.58 |
| W. TV |
2.32 |
0.00 |
35.80 |
| W. Plant |
0.00 |
0.00 |
100.00 |
|
Average
|
39.83 |
24.57 |
69.06 |
| OSF: Ontology-based Semantic Fusion |
Figure
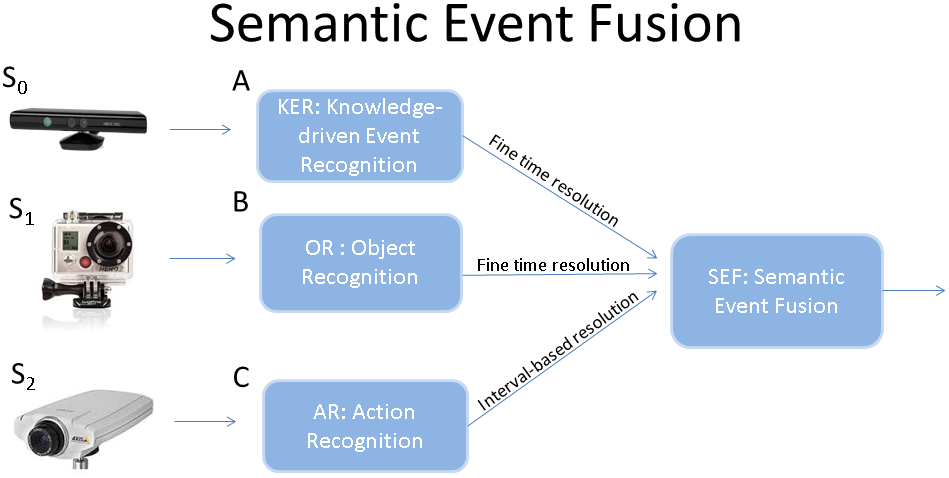
19. Semantic event fusion framework: detector modules (A-C) process data from their respective sensors (S0-S2) and output concepts (objects and low-level events). Semantic Event Fusion uses the ontological representation to initialize concepts to event models and then infer complex, composite activities. Concept fusion is performed on millisecond temporal resolution to cope with instantaneous errors of concept recognition.
|
|
Figure
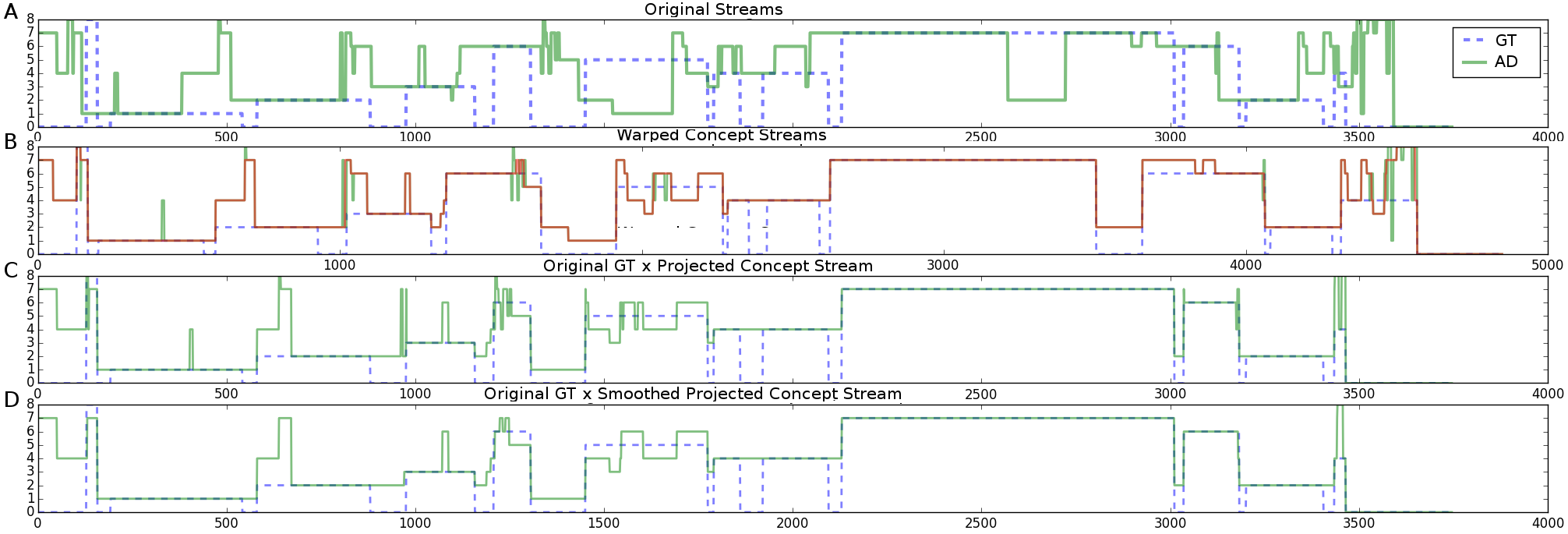
20. Semantic alignment between the concept stream of the action recognition detector (AR) and a concept stream (GT) generated from events manually annotated by domain experts using the time axis of the color-depth camera. X-axis denotes time in frames, and Y-axis denotes activity code (1-8), respectively, search bus line on the map, establish bank account balance, prepare pill box, prepare a drink, read, talk on the telephone, watch TV, and water the plant. From top to bottom, images denote: (A) original GT and AR streams, (B) GT and AR streams warped, AR stream warped and smoothed (in red), (C) original GT and AR stream warped and then backprojected onto GT temporal axis, (D) original GT and AR warped, backprojected, and then smoothed with median filtering.
|
|